L'archeologia moderna, sempre più orientata verso la quantificazione e la gestione di enormi moli di dati, si avvale in maniera crescente di strumenti informatici avanzati. Tra questi, i database relazionali giocano un ruolo cruciale nell'organizzazione, nell'archiviazione e nell'analisi delle informazioni raccolte sul campo e in laboratorio. Un database, in termini generali, è un archivio di dati, prevalentemente alfanumerici, riguardanti uno stesso argomento o più argomenti correlati tra loro. La sua gestione, che implica operazioni di inserimento, modifica e ricerca, viene svolta per mezzo di appositi software. I sistemi di gestione di database (DBMS) sono progettati per gestire grandi quantità di dati, condivisibili da diverse applicazioni e da una pluralità di utenti, e incrementabili senza restrizioni.
I dati possono essere distribuiti tra diversi calcolatori collegati in rete, e negli ultimi anni le banche dati si sono sempre più integrate con Internet. Molti siti web sono strutturati come database, come ad esempio gli OPAC (Online Public Access Catalogue), che sono cataloghi elettronici delle biblioteche. La creazione e la gestione di una grande base di dati, che include la facoltà di modificarne i contenuti, è a cura del suo Amministratore, definito DBA (Data Base Administrator). Gli utenti, d'altra parte, accedono all'archivio per consultarlo.
Sul mercato si sono imposti diversi software per la gestione delle basi di dati. Alcuni sono relativamente facili da usare, come Access e FileMaker, mentre altri sono di tipo professionale, tra cui MS SQL Server, Oracle, Informix e IBM DB2. Molti sono anche i software open source; il più diffuso al mondo è MySQL, seguito da PostgreSQL. In Italia si è affermato anche picoSQL, prodotto dalla Picosoft di Pisa. Alla vasta schiera di programmi gratuiti si è aggiunto recentemente StarOffice Base, inserito nel pacchetto StarOffice scaricabile liberamente, di uso molto semplice e simile ad Access per interfaccia e procedure.
Per interagire con il database, la maggior parte dei programmi mette a disposizione ambienti operativi user-friendly con tabelle e maschere. I software di tipo professionale sono dotati anche di una riga di comando in cui si può lavorare in SQL (Structured Query Language), un linguaggio internazionale standard per la gestione delle basi di dati. MySQL presenta un ambiente grafico essenziale comprendente esclusivamente la riga di comando; tuttavia, è possibile scaricare un altro software, MySQL GUI Tools, che offre gli strumenti per sviluppare al suo interno un'interfaccia amichevole.
Struttura Fondamentale di un Database Relazionale
Una base di dati è composta da uno o più archivi, che sono insiemi di dati omogenei, strutturati in forma di tabelle. Aprendo un file di un database, viene solitamente visualizzata una finestra dove sono elencate le tabelle che ne fanno parte. Facendo doppio clic sull'icona di una di esse, ne viene visualizzato il contenuto.
La tabella, nella sua modalità di visualizzazione ordinaria, ha la forma di un foglio elettronico, organizzato per righe e colonne. Le righe vengono definite "record" e rappresentano le varie entità dell'archivio; le colonne, definite "campi", sono gli attributi delle entità. Ad esempio, nella tabella delle unità stratigrafiche di uno scavo, ogni record corrisponde a una determinata US (Unità Stratigrafica), identificata dal relativo numero; i campi sono le singole voci della scheda (definizione e posizione, criteri di distinzione, modo di formazione, ecc.).
Un comando su una delle barre degli strumenti permette di visualizzare la struttura della tabella. In questa finestra vengono specificate le caratteristiche dei vari campi e se ne possono creare di nuovi. È necessario stabilire il tipo di dati che devono essere contenuti in ogni campo (numerici, di testo, data e ora, di collegamento ipertestuale, memo, ecc.) e il numero massimo di caratteri numerici o di testo consentito per ogni campo (dimensione campo).
Nel caso di testi molto lunghi, come quelli relativi alle voci "descrizione", "osservazione" e "interpretazione" delle schede US, è conveniente impostare un tipo di comando che consenta di scrivere testo senza limiti, definito "memo" sia in Access che in StarOffice Base. Gli archivi possono contenere anche immagini.
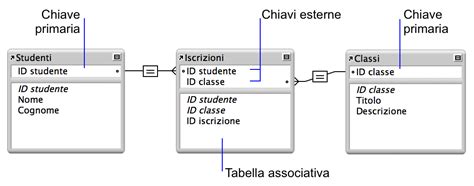
Ogni record della tabella dovrà inoltre distinguersi da tutti gli altri per mezzo di un numero identificativo (ID). Questo numero si basa su una numerazione progressiva a riempimento automatico che non è possibile modificare (contatore). Deve essere creato un apposito campo per l'ID, che viene normalmente denominato con due lettere seguite dal nome della tabella o da una sigla che consenta di distinguerlo dagli ID delle altre tabelle del database (ad esempio, nella tabella delle unità stratigrafiche, sarà denominato IdUS). Al campo ID viene assegnata anche una chiave primaria (accanto alla quale viene visualizzata un'icona con una chiave). Questa funzione controlla che il numero identificativo sia sempre diverso per ogni record, anche in caso di cancellazioni e modifiche, garantendo l'unicità di ogni registrazione.
Interfacce Utente: Dall'Efficienza alla Chiarezza
La tabella in formato "foglio dati" è un ambiente di lavoro alquanto scomodo sia per immettere dati che per visualizzarli, soprattutto se composta da numerosi campi, alcuni dei quali destinati a contenere una grande quantità di caratteri di testo. Per ovviare a questo problema, si utilizzano le maschere.
Una maschera è una finestra che visualizza i dati pertinenti a un singolo record, ovvero a un'entità del database. Nella schermata appaiono le intestazioni dei vari campi in associazione a delle caselle contenenti i dati relativi al record selezionato in quel momento. Per immettere o modificare i dati, si selezionano le relative caselle con il puntatore e si scrive al loro interno. Delle frecce di scorrimento poste sulla barra di stato in basso permettono di spostarsi tra un record e l'altro.
Le maschere possono essere create in maniera quasi automatica tramite una procedura guidata. Tuttavia, la forma della maschera così creata potrebbe non risultare soddisfacente. È quindi possibile trasformarla per mezzo di una serie di strumenti di editing che consentono di modificare la forma e le dimensioni delle etichette (intestazioni dei campi) e delle relative caselle di testo. Si possono anche aggiungere titoli, intestazioni a piè di pagina, pulsanti di comando, sottomaschere, simboli grafici e numerosi altri elementi.
La progettazione delle maschere è un'operazione importante quando si costruisce un grande database, in quanto questa sarà l'interfaccia adoperata da un gran numero di utenti per accedere ai vari contenuti dell'archivio. Deve essere dotata di pulsanti che consentano l'apertura di altre tabelle, lo svolgimento di interrogazioni e l'accesso a file d'immagine. Le finestre che contengono lunghi testi scritti dovranno avere dimensioni adeguate; l'uso appropriato del colore aiuta a identificare i vari elementi, e la disposizione delle etichette e delle relative caselle deve seguire un ordine logico.
Le informazioni vanno organizzate con criteri razionali che facilitino l'immissione dei dati, semplifichino le ricerche ed evitino errori di compilazione. Le informazioni principali, che specificano in maniera sintetica le caratteristiche dell'entità catalogata (ad esempio, definizione, posizione, tipo, ecc.) e che sono più comunemente oggetto di ricerca tramite apposite interrogazioni, devono essere compilate facendo ricorso a una terminologia univoca, rigorosa e coerente. È conveniente pertanto predisporre in alcuni campi della maschera le cosiddette "caselle combinate", le quali contengono un elenco predefinito di parole; l'utente dovrà necessariamente sceglierne una e non potrà immettervi caratteri di testo.
MS Access creazione di una maschera di inserimento dati
Altri due ambienti operativi frequentemente utilizzati all'interno di un database sono le query e i report. Le prime sono delle tabelle strutturate per effettuare ricerche nel database tramite interrogazioni. I report, invece, sono documenti formattati per la presentazione dei dati, utili per la stampa o per l'esportazione in altri formati.
Relazioni tra Tabelle: Connettere i Dati per una Visione Integrata
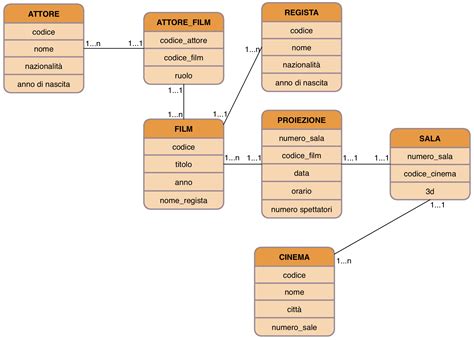
Nei database relazionali, è possibile istituire dei collegamenti tra tabelle utilizzando dei campi comuni costituiti dagli identificatori. Il collegamento viene attuato in un'apposita finestra del database, attivabile per mezzo del comando "Relazioni", dove vengono mostrate tutte le tabelle con l'elenco dei rispettivi campi.
Esistono principalmente due tipi di relazioni:
Relazione Uno-a-Molti (1:N): Questa relazione collega un record dell'archivio principale a un numero illimitato di record dell'archivio secondario. Ad esempio, un unico record nella tabella dei siti archeologici (archivio principale) potrebbe essere collegato a molti record nella tabella delle unità stratigrafiche (archivio secondario) trovate in quel sito. Il risultato di questo collegamento è che tutte le tabelle secondarie sono visualizzabili e modificabili anche all'interno della tabella principale. La visualizzazione dell'archivio secondario può avvenire anche dalla maschera dell'archivio principale, per mezzo di pulsanti appositamente progettati.
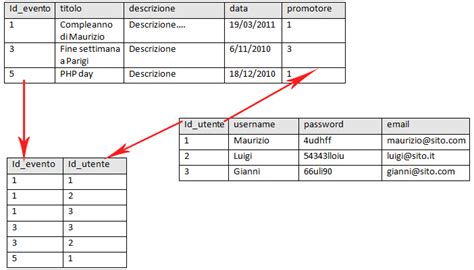
Relazione Molti-a-Molti (N:M): In questo caso, un singolo record della tabella A può collegarsi a molti record della tabella B, e contemporaneamente un singolo record della tabella B può essere in relazione con molti record della tabella A. Per istituire questo tipo di relazione, è necessario creare una tabella intermedia contenente gli ID di entrambe le tabelle A e B, e allacciare per mezzo di questa i reciproci collegamenti. Ad esempio, in un archivio di presenze archeologiche, un archivio bibliografico e un archivio di immagini possono essere collegati con relazioni di tipo molti-a-molti per mezzo di tre tabelle intermedie contenenti i vari ID di quelle principali. In questo modo, sarà possibile accedere dall'archivio delle presenze archeologiche a molti dati bibliografici relativi a una singola presenza.
Le relazioni di tipo molti-a-molti danno luogo a collegamenti orizzontali, favorendo una navigazione più libera e articolata del database.
Le banche dati di grandi dimensioni, costituite da decine di tabelle e migliaia di dati, fanno necessariamente ricorso a entrambi i tipi di relazioni e richiedono un'intelligente progettazione a priori, in modo da valutare tutte le esigenze dei potenziali utilizzatori e organizzare di conseguenza i necessari percorsi di navigazione. Occorre inoltre sempre tenere conto del fatto che il database progettato può essere destinato a integrarsi con altri archivi all'interno di sistemi informativi più complessi, e quindi bisogna garantirne l'interoperabilità.
Applicazioni Archeologiche di Database Relazionali
L'applicazione dei database relazionali in archeologia è vasta e diversificata, spaziando dalla gestione dei dati di scavo alla catalogazione di manufatti, dalla ricostruzione di paesaggi antichi alla gestione di archivi bibliografici e fotografici.
Un esempio significativo è l'architettura del database della Carta Archeologica della Valle del Sinni, in Basilicata, realizzata dalla Cattedra di Topografia Antica della Seconda Università di Napoli e dalla Cattedra di Topografia dell'Italia Antica dell'Università di Bologna. La grande quantità di tabelle e i relativi collegamenti sono organizzati secondo uno schema logico che tiene conto delle esigenze dei ricercatori. Il perno del database è costituito dalla tabella delle presenze, collegata direttamente alla cartografia, e costituisce quindi il punto più importante di scambio tra i dati alfanumerici e la loro rappresentazione cartografica. Il numero delle tabelle è commisurato alle tipologie rintracciate sul terreno. Il sistema può essere modificato in ogni momento operando accorpamenti o introducendo nuove tabelle. La complessità di tale struttura resta ignota all'utente, il quale navigherà all'interno del database per mezzo di maschere user-friendly.
Il Geoportale Nazionale per l'Archeologia (GNA) costituisce un altro esempio di sistema integrato per la raccolta e la condivisione online dei dati esito delle indagini archeologiche condotte sul territorio italiano. La mappa principale pubblica i dati relativi agli interventi di tutela svolti sotto la Direzione Scientifica del MiC: indagini archeologiche preventive, scavi in assistenza, studi territoriali, rinvenimenti fortuiti. Le informazioni pubblicate provengono dal censimento dei dati d'archivio delle Soprintendenze e dalle relazioni archeologiche preventive. La sezione "Altre banche dati" accoglie dati elaborati nell'ambito di progetti di ricerca volontaria, con l'obiettivo di ampliare la visibilità e la conoscibilità delle informazioni sul patrimonio archeologico.
Altri progetti evidenziano l'uso di database per la gestione di specifici tipi di reperti o contesti:
- Archeologia dei Paesaggi Medievali: Progetti di ricerca hanno portato alla creazione di database per analizzare la distribuzione e le caratteristiche degli insediamenti, delle fortificazioni e delle strutture produttive in epoche medievali.
- Catalogazione di Manufatti: Database specifici vengono creati per catalogare reperti ceramici, metallici, ossei o litici, associando a ciascun oggetto informazioni dettagliate sulla provenienza, datazione, caratteristiche morfologiche e analisi di laboratorio.
- Gestione di Reperti Archeozoologici: Archivi informatizzati per la gestione dei reperti archeozoologici permettono di analizzare le faune antiche, fornendo dati preziosi per la ricostruzione delle diete, delle pratiche di allevamento e dell'ambiente antico.
- Atlanti Informatizzati: La creazione di atlanti informatizzati di siti archeologici, come quelli relativi ai siti fortificati d'altura della Toscana, sfrutta database relazionali per integrare dati cartografici, descrittivi e fotografici.
La progettazione di uno schema di database efficace per l'archeologia richiede una profonda comprensione delle specificità dei dati archeologici e delle esigenze dei ricercatori. Questo processo si articola tipicamente in tre fasi:
- Schema Concettuale: Una visione di alto livello che definisce le entità principali (es. sito, unità stratigrafica, manufatto) e le loro relazioni, allineandosi agli interessi generali del progetto.
- Schema Logico: Una struttura dati dettagliata che rappresenta lo schema concettuale, includendo tabelle, relazioni, tipi di dati, chiavi primarie ed esterne, e vincoli di integrità. Questa fase è indipendente dal sistema di database specifico.
- Schema Fisico: La rappresentazione concreta di come i dati verranno archiviati e acceduti in un sistema di database specifico, includendo dettagli su strutture di archiviazione, file e configurazioni della piattaforma.
L'utilizzo di database relazionali, con le loro capacità di definire schemi precisi e relazioni rigorose, è fondamentale per garantire l'integrità, la coerenza e l'accessibilità dei dati archeologici, aprendo nuove prospettive per la ricerca e la valorizzazione del patrimonio culturale.
tags: #database #relazionale #gs #archeologia #schema