Il mondo della gestione dei dati è intrinsecamente legato a due pilastri fondamentali: l'algebra relazionale e il linguaggio SQL (Structured Query Language). Sebbene entrambi siano nati con lo scopo comune di manipolare e interrogare basi di dati relazionali, presentano differenze sostanziali che riflettono la loro evoluzione e il loro utilizzo pratico. Comprendere il passaggio dall'uno all'altro è cruciale per chiunque si addentri nel campo dell'informatica e delle basi di dati.
Le Fondamenta Teoriche: L'Algebra Relazionale
L'algebra relazionale, nella sua essenza, è un linguaggio formale e teorico per la manipolazione di dati organizzati in relazioni, che sono concettualmente simili a tabelle. Essa si basa su un insieme di operazioni primitive che operano su queste relazioni per produrre nuove relazioni. Queste operazioni includono:
- Selezione (σ): Permette di filtrare le righe di una relazione in base a una condizione specificata. Ad esempio, selezionare tutti i clienti che vivono in una determinata città.
- Proiezione (π): Consente di selezionare specifiche colonne (attributi) da una relazione, eliminando quelle non desiderate. Ad esempio, ottenere solo i nomi e gli indirizzi dei clienti, scartando altre informazioni.
- Unione (∪): Combina le righe di due relazioni che hanno gli stessi attributi. È simile all'unione di insiemi matematici.
- Intersezione (∩): Restituisce le righe che sono presenti in entrambe le relazioni.
- Differenza (-): Produce le righe presenti nella prima relazione ma non nella seconda.
- Prodotto Cartesiano (×): Combina ogni riga della prima relazione con ogni riga della seconda relazione, creando una nuova relazione con un numero di colonne pari alla somma delle colonne delle due relazioni originali.
- Ridenominazione (ρ): Permette di cambiare il nome di una relazione o dei suoi attributi.
- Join (⋈): Un'operazione fondamentale che combina le righe di due relazioni in base a una condizione di uguaglianza tra attributi correlati. Esistono diversi tipi di join, come il natural join, il theta join e l'equijoin.
Un aspetto distintivo dell'algebra relazionale è la sua natura insiemistica. Per definizione, una relazione in algebra relazionale è un insieme di tuple (righe), e come tale, non ammette valori duplicati. Ogni tupla è unica. Questo deriva direttamente dal concetto di relazione matematica, dove gli elementi di un insieme sono distinti.
Inoltre, l'algebra relazionale è intrinsecamente procedurale. Le operazioni vengono eseguite in una sequenza specifica per ottenere il risultato desiderato. Si definisce un "percorso" per arrivare alla risposta.
Il Linguaggio di Interrogazione Universale: SQL
SQL, al contrario dell'algebra relazionale, è un linguaggio di programmazione progettato per la gestione dei dati in sistemi di gestione di basi di dati relazionali (RDBMS). La sua forza risiede nella sua versatilità e nel suo utilizzo pratico in una vasta gamma di applicazioni. SQL è un linguaggio sia DML (Data Manipulation Language), utilizzato per inserire, aggiornare, cancellare e recuperare dati, sia DDL (Data Definition Language), impiegato per definire la struttura delle tabelle, creare indici e gestire i permessi.
A differenza dell'algebra relazionale, SQL è un linguaggio dichiarativo. Invece di specificare la sequenza esatta di operazioni da eseguire (come farebbe un approccio procedurale), l'utente dichiara "cosa" desidera ottenere, e il sistema di gestione della base di dati (DBMS) si occupa di determinare il modo più efficiente per farlo. Questo trasferimento di responsabilità al DBMS è uno dei motivi principali per cui SQL è così ampiamente adottato.
Un'altra differenza cruciale riguarda la gestione dei duplicati. Il linguaggio SQL ammette valori duplicati nelle tabelle. La ragione di questa scelta risiede nell'efficienza. L'eliminazione dei duplicati è un'operazione computazionalmente costosa, che spesso richiede l'ordinamento dei dati e un ulteriore elaborazione. Poiché in molte situazioni l'eliminazione dei duplicati non è strettamente necessaria, SQL, per impostazione predefinita, non li rimuove.
Quando si eseguono interrogazioni in SQL, la clausola SELECT ALL, o semplicemente SELECT (poiché ALL è implicito di default), seleziona tutte le righe che soddisfano i criteri, inclusi eventuali duplicati. Per ottenere un risultato privo di duplicati, è necessario utilizzare esplicitamente la clausola DISTINCT.
Esempio:
-- Seleziona tutte le righe, inclusi i duplicatiSELECT * FROM TabellaClienti;-- Seleziona solo le righe uniche in base alla colonna NomeSELECT DISTINCT Nome FROM TabellaClienti;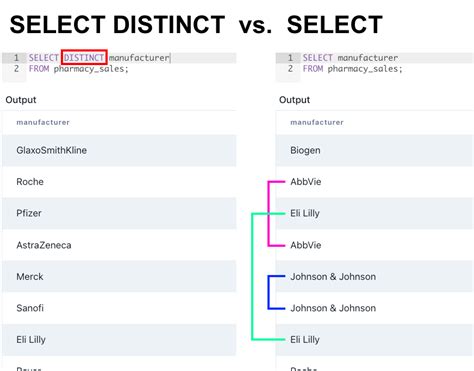
SQL offre una ricca gamma di operatori aggregati per eseguire calcoli su insiemi di righe:
COUNT(): Conta il numero di righe.SUM(): Somma i valori di una colonna numerica.AVG(): Calcola la media dei valori di una colonna numerica.MAX(): Trova il valore massimo in una colonna.MIN(): Trova il valore minimo in una colonna.
Questi operatori permettono di sintetizzare grandi quantità di dati in informazioni significative.
Interrogazioni Equivalenti e l'Ottimizzazione delle Query
Un concetto chiave sia nell'algebra relazionale che in SQL è quello delle interrogazioni equivalenti. Esistono infatti diverse strade, o "forme", per raggiungere lo stesso risultato finale. Ad esempio, una join complessa può talvolta essere scomposta in operazioni più semplici, o viceversa.
Un aspetto importante da notare è che l'optimizer delle query (il componente del DBMS responsabile dell'ottimizzazione delle interrogazioni) non cerca necessariamente la forma assolutamente ottimale, la migliore possibile in assoluto. La ricerca di tale ottimalità richiederebbe tempi di elaborazione proibitivi. Invece, l'optimizer utilizza euristiche e algoritmi per trovare una soluzione che sia sufficientemente efficiente e che possa essere eseguita in un tempo ragionevole.
Questo principio si riflette anche nella pratica di sviluppo. Spesso, più query SQL possono produrre lo stesso output. La scelta tra queste dipenderà da fattori quali la leggibilità del codice, la familiarità del team di sviluppo con una particolare sintassi e le prestazioni osservate nel contesto specifico del database.
La Sfida della Trasformazione: Dall'Algebra Relazionale a SQL in Pratica
La conversione diretta di un'espressione di algebra relazionale in una query SQL non è sempre banale. Sebbene ci sia una forte corrispondenza concettuale, le differenze nella sintassi e nella gestione dei duplicati richiedono attenzione.
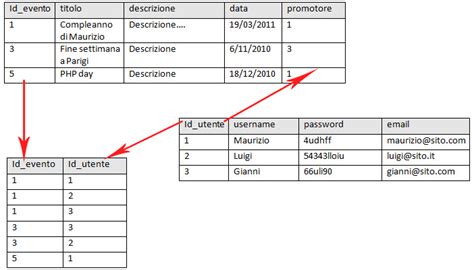
Consideriamo un esempio pratico. Supponiamo di avere due tabelle: Album (con campi CodiceAlbum, TitoloAlbum, AnnoUscita) e Vendite (con campi CodiceAlbum, CopieVendute).
In algebra relazionale, potremmo voler trovare il numero totale di copie vendute per ogni album uscito dopo un certo anno. Questo potrebbe essere espresso come:
π TitoloAlbum, SUM(CopieVendute) ( σ AnnoUscita > 2000 ( Album ⋈ Vendite ) )
Dove:
Album ⋈ Venditeesegue un join tra le due tabelle.σ AnnoUscita > 2000 (...)seleziona solo gli album usciti dopo il 2000.SUM(CopieVendute)aggrega le copie vendute.π TitoloAlbum, ...proietta solo il titolo dell'album e il totale delle vendite.
In SQL, la traduzione potrebbe essere:
SELECT A.TitoloAlbum, SUM(V.CopieVendute) AS TotaleVenditeFROM Album AJOIN Vendite V ON A.CodiceAlbum = V.CodiceAlbumWHERE A.AnnoUscita > 2000GROUP BY A.TitoloAlbum;Qui, il JOIN in SQL corrisponde all'operazione di join nell'algebra relazionale. La clausola WHERE filtra i risultati in base all'anno di uscita. La clausola GROUP BY e la funzione aggregata SUM() svolgono il ruolo dell'aggregazione e della proiezione finale.
Un esempio più complesso, come discusso in un forum, riguarda la gestione di duplicati e relazioni tra tabelle. La richiesta di trasformare una struttura dati ipotetica, possibilmente con relazioni implicite, in una query SQL evidenzia le sfide pratiche. La conversione di un "codice" (presumibilmente un identificatore univoco) in SQL, insieme ad altri attributi come Titolo, Album, Anno, CopieVendute, richiede una chiara definizione delle tabelle e delle loro chiavi primarie/esterne.
Se l'obiettivo è identificare duplicati, SQL offre strumenti specifici. Una "query di ricerca duplicati" può essere creata per puntare su una coppia di campi (ad esempio, Cantante e Anno) per individuare record con combinazioni identiche, dimostrando come SQL possa affrontare scenari che nell'algebra relazionale sarebbero gestiti attraverso operazioni insiemistiche più astratte.
Considerazioni Aggiuntive e Applicazioni Moderne
Sebbene l'algebra relazionale rimanga un fondamento teorico essenziale, il suo impatto diretto sull'uso quotidiano è minore rispetto a SQL. Tuttavia, la comprensione dei suoi principi è fondamentale per chiunque desideri approfondire la progettazione di basi di dati, l'ottimizzazione delle query e la teoria dei database.
Nel contesto delle applicazioni web moderne, la gestione dei dati è spesso complessa. Tecnologie come i browser "headless" e le tecniche di scraping sollevano nuove sfide. L'idea che "a livello individuale il carico aggiuntivo sia trascurabile, ma a livelli di scraper di massa si sommi e renda lo scraping molto più costoso" suggerisce un approccio basato sulla generazione di un carico computazionale aggiuntivo per i bot. Questo può essere ottenuto attraverso l'uso di funzionalità JavaScript moderne che plugin come JShelter potrebbero disabilitare, rendendo più difficile per gli scraper identificare e sfruttare le vulnerabilità.
Questo scenario evidenzia come le sfide nell'interazione tra sistemi possano portare a soluzioni innovative che vanno oltre le tradizionali operazioni di database. Il focus si sposta sull'identificazione di pattern comportamentali, come il rendering dei font da parte dei browser headless, al fine di distinguere utenti legittimi da bot automatizzati, evitando così la presentazione di sfide come "proof of work" a utenti potenzialmente legittimi.
Come fare Scraping Velocemente e Senza Codice - BrowseAI
In sintesi, il passaggio dall'algebra relazionale a SQL rappresenta un'evoluzione dalla teoria astratta alla pratica applicativa. Mentre l'algebra relazionale fornisce il linguaggio matematico per definire le operazioni sui dati, SQL offre gli strumenti pratici per implementarle in modo efficiente e flessibile, adattandosi alle esigenze sempre più complesse della gestione delle informazioni nell'era digitale.